로그-멜 스펙트로그램은 한마디로 사람의 청각 특성을 반영하여 음성 데이터를 시각적으로 표현한 이미지라고 할 수 있습니다. 컴퓨터가 음성을 더 잘 이해하도록 가공한 데이터 형태이죠. 이를 이해하기 위해 '스펙트로그램', '멜 스케일', '로그 스케일' 세 가지로 나누어 살펴보겠습니다.
1. 스펙트로그램 (Spectrogram)
음성은 시간에 따라 계속 변하는 복잡한 파동입니다. 이 파동을 그대로 분석하기는 어렵기 때문에, 컴퓨터는 '푸리에 변환(Fourier Transform)'이라는 수학적 도구를 사용해 음성을 여러 주파수(음의 높낮이) 성분으로 분해합니다.
스펙트로그램은 이 분해된 결과를 시각화한 것입니다.
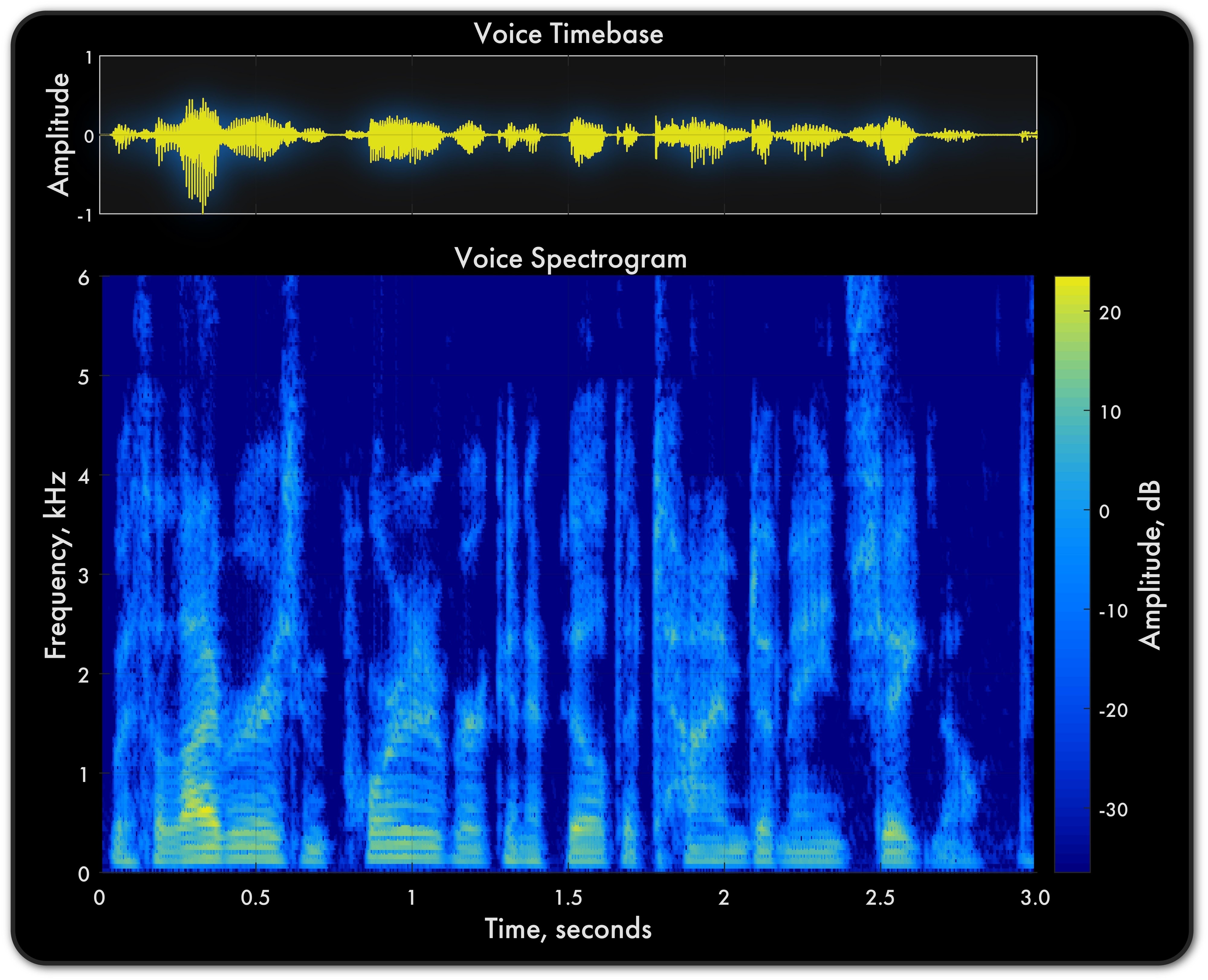
- 가로축은 시간의 흐름을 나타냅니다.
- 세로축은 주파수(Hz)를 나타냅니다. (아래쪽이 저주파, 위쪽이 고주파)
- 색깔은 해당 시간과 주파수에서의 **소리의 세기(진폭)**를 나타냅니다. (밝을수록 강한 소리)
즉, 스펙트로그램을 보면 어떤 시간에 어떤 높이의 소리가 얼마나 강하게 났는지를 한눈에 파악할 수 있습니다. 마치 악보처럼 음성의 시간과 높낮이 정보를 담고 있는 셈이죠.
2. 멜 스케일 (Mel Scale)

사람의 귀는 소리의 높낮이를 선형적으로 인식하지 않습니다. 예를 들어, 100Hz와 200Hz의 차이는 명확하게 구분하지만, 10000Hz와 10100Hz의 차이는 거의 구분하지 못합니다. 즉, 저주파수 대역에서는 민감하게 반응하고, 고주파수 대역에서는 둔감하게 반응합니다.
멜 스케일은 이러한 사람의 청각 특성을 수학적으로 모델링한 주파수 척도입니다. 일반적인 주파수(Hz)를 멜 스케일로 변환하면, 사람이 민감하게 느끼는 저주파수 대역은 넓게 표현하고, 둔감하게 느끼는 고주파수 대역은 좁게 표현할 수 있습니다.
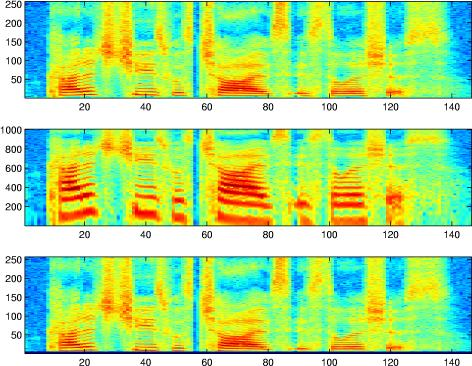
스펙트로그램에 멜 스케일을 적용하여 멜 스펙트로그램(Mel Spectrogram)을 만들면, 기계(컴퓨터)가 사람처럼 음성의 중요한 특징(주로 저주파수 대역에 분포)에 더 집중하여 학습할 수 있게 됩니다.
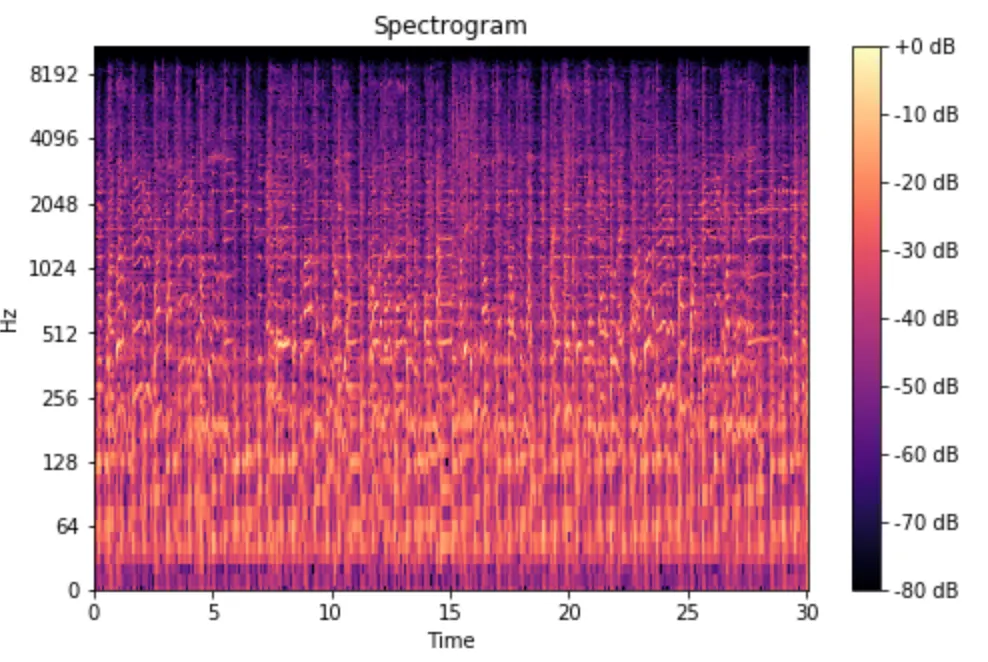
3. 로그 스케일 (Log Scale)
소리의 세기(진폭) 역시 사람이 인식하는 방식은 선형적이지 않습니다. 아주 작은 소리의 변화는 민감하게 감지하지만, 매우 큰 소리의 변화는 상대적으로 둔감하게 느낍니다. 이는 데시벨(dB) 단위가 로그(Log)를 사용하는 이유와 같습니다.
멜 스펙트로그램의 색깔로 표현되는 소리의 세기 값에 로그 변환을 적용하면, 이러한 사람의 인식 방식과 유사하게 만들어 줄 수 있습니다. 즉, 소리의 세기 차이를 사람이 듣는 것과 비슷하게 표현하여, 너무 크거나 작은 소리 값에 모델이 과도하게 영향을 받는 것을 막아줍니다.
결론: 로그-멜 스펙트로그램이란?
결론적으로 로그-멜 스펙트로그램은 다음과 같은 과정을 거쳐 만들어집니다.
- 음성 파동을 시간-주파수 정보로 변환하여 스펙트로그램을 만듭니다.
- 주파수 축을 사람이 듣는 방식과 유사한 멜 스케일로 변환합니다.
- 소리의 세기 축을 사람이 인지하는 방식과 유사한 로그 스케일로 변환합니다.
"음성 신호를 시간, 높낮이, 강도를 보여주는 스펙트로그램으로 만든 뒤, 사람이 소리를 인지하는 방식처럼
①높낮이는 멜 스케일로, ②강도는 로그 스케일로 변환하여,
컴퓨터가 인간의 청각처럼 중요한 특징을 더 잘 학습할 수 있는 숫자 형태(이미지)로 만드는 것"
이렇게 만들어진 로그-멜 스펙트로그램은 원본 음성 데이터의 핵심적인 특징을 잘 담고 있으면서도, 사람이 소리를 인식하는 방식을 모방했기 때문에 Whisper와 같은 음성 인식 모델이 훨씬 더 효율적으로 학습하고 높은 성능을 낼 수 있도록 돕는 매우 중요한 전처리(preprocessing) 단계입니다.
참고자료